
Evading Anomaly-Based NIDS with Empire
In DEF CON 26, I gave a speech about this topic on Packet Hacking Village, and demonstrated my tool (firstorder) in Demo Labs. I got very good feedbacks for my idea, however some people seem to be confused about all these. So I want to explain everything in a blog post for better understanding. If you detect anything wrong or if you have some better ideas, please let me know.
TL;DR
We wrote a tool called firstorder, which analyses the network traffic and identifies normal traffic profile. With this information, it configures Empire’s listener. So with this listener, we have a good chance to evade listener-agent communication from an -application layer- anomaly based NIDS, since we are matching with normal traffic profile.
Introduction
Since the beginning of computer security history, perimeter defenses (firewalls etc.) are playing an important role. But as we can observe from recent breaches, perimeter defenses are not holding attackers out from an organization’s network. A good crafted spear-phishing e-mail usually enough to gain a foothold on the network. More and more attackers are using these techniques to bypass these defenses.
As attacker profile has been changed by time, traditional defense approaches are changing too. Today, organizations and red teams are mostly focused on ”assume breach” approach. Assume breach is simply accepting that, attackers are bypassed your perimeter defenses and got a foothold on your network. So, an organization should focus on defense strategies as per that way. Also, red teams will be focused on post-exploitation instead of passing perimeter defenses. So rather than traditional vulnerability scanning, testing activities becomes a cat and mouse game between attackers and defenders.
NIDS (Network Intrusion Detection Systems)
We can show NIDS as an initial step for detecting attackers on the network. We can talk about two main types of NIDS: they are signature-based and anomaly-based.
Signature-Based
Signature-based NIDS refers to the detection of attacks by looking for pre-defined patterns of previously known attacks. They compares each network packet with those pre-defined patterns. If they match, we have a malicious traffic. There are very good and open source projects out there such as Snort and Suricate. The downside of these systems is since they only catch known attacks, they won’t be able to catch new type of attacks.
So how can we evade a signature-based system? We shouldn’t match with any pre-defined pattern. All we have to do is changing the traffic elements such as packet size, headers and some known strings, maybe we can apply some encoding methods, and we are good to go.
Anomaly-Based
Anomaly based systems are bit sophisticated than signature based systems. Anomaly-based NIDS refers to building a statistical model describing the normal network traffic, and flagging the abnormal traffic. To do that, it analyzes the normal network traffic (like daily user activities) and applies various data science techniques to build a pattern. These kind of systems are exists, but they are usually commercial products not open source projects. There are also some theoretical concepts described in various of researches but they are not practical yet. Anomaly-based system have a chance to catch new type of attacks.
We can show the overall process in a basic chart:
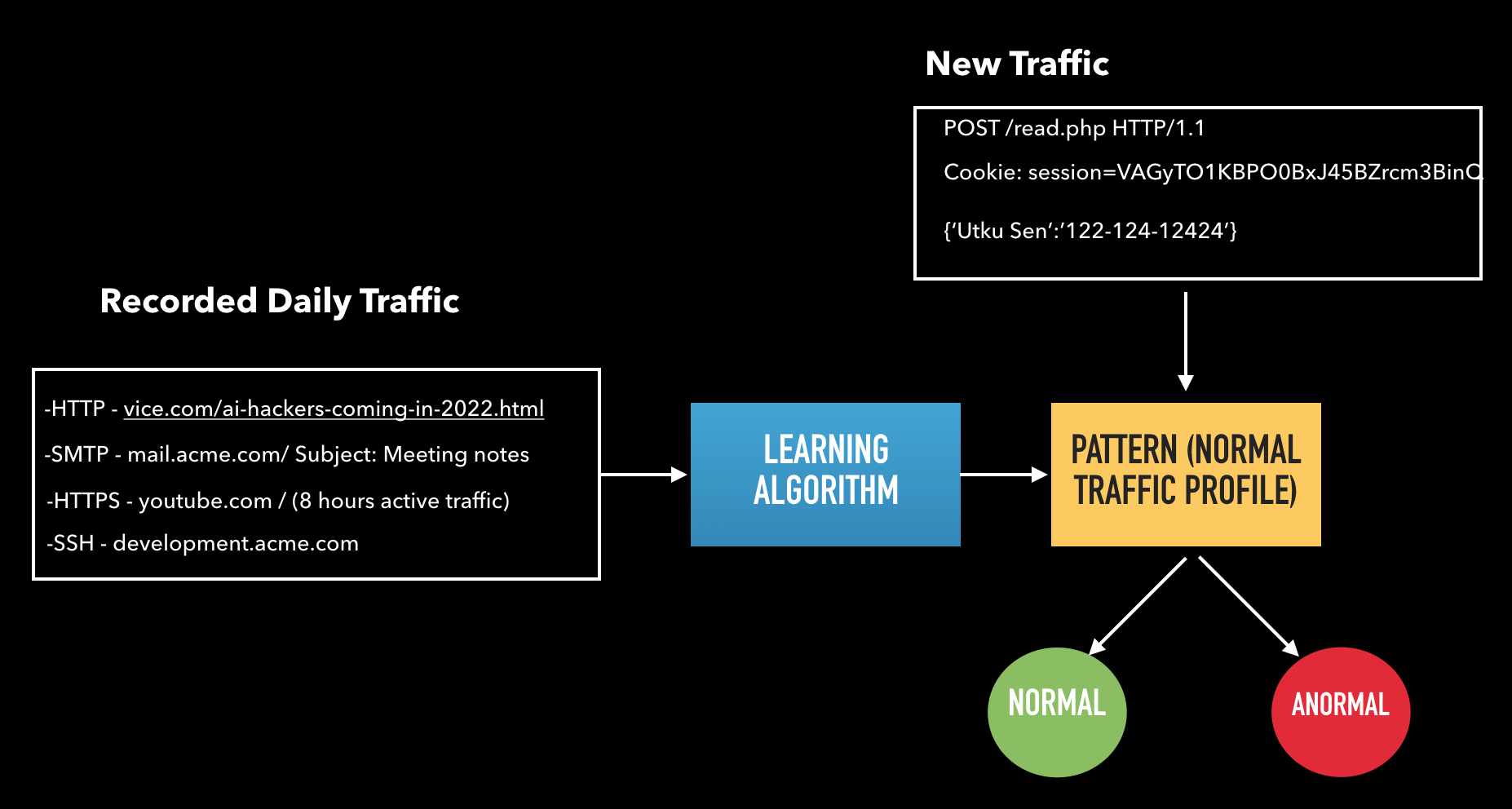
Anomaly-based system should record the daily traffic first. What do we mean by daily traffic? It can be visiting a news website, sending an e-mail via SMTP or accessing a server via SSH etc. After then, that capture data will be given to the learning algorithm. Algorithm will be trained by this data to create the normal traffic profile. After then, this program listens to network traffic and compares each packet with the normal traffic profile. If it’s not fit the normal profile, it flags it as anormal traffic.
The evasion part is a bit tricky than the signature-based systems. We can list the evasion methods into two different category: pre-training evasion and post-training evasion. Let’s start with pre-training evasion.
As we know that anomaly based system needs to capture and analyze a regular network traffic in order to build a pattern. So we are assuming that during traffic capture, only legit users are generating legit network traffic. So that we are expecting that anomaly based system will be able to differentiate malicious traffic from normal traffic. But what if an attacker is located on the network before the traffic training process? He can generate malicious traffic, and it will be included in the normal traffic pattern.
For example let’s say a user visits amazon.com, another one makes a SSH connection, but the attacker generates meterpreter’s reverse tcp traffic. Anomaly based system will include this on the normal profile. So in future, when anyone run Meterpreter on the network, anomaly based system won’t detect it. But we can say this scenario is not realistic. How can an attacker knows when the traffic is gonna be trained? It’s hard. We can count this under malicious insider threat.
In a realistic scenario, we expect that attacker can’t know when the traffic training is done. Therefore, we need to focus on post-training evasion. In this scenario we will assume that a trained anomaly based system watches the whole network. So we, as an attacker should establish C2-agent communication and exfiltrate data without causing any anomaly alert.
Empire Project
We need a post-exploitation framework for attacking purposes. We will stick with Empire for this. Empire is a PowerShell and Python based post- exploitation framework which is designed for ”assume breach” type of activities. We can describe Empire’s workflow in two parts: Agent and listener. Agent states the infected machine on the network which takes and executes given tasks on there. Listener is described as a communication server in which agent connects there, gets designated task and sends related output.
Empire supports HTTP and HTTPS (also Dropbox etc.) listeners for C2-agent communication. Even tough HTTPS connection encrypts all communication, we will assume there is a solution on the network which intercepts and decrypts SSL/TLS traffic. Because of that, HTTP listener will be the main focus.
HTTP listener has following key options:
-
KillDate: Date for the listener to exit
-
DefaultDelay: Agent delay/reach back interval
-
WorkingHours: Hours for the agent to operate
-
DefaultProfile: User-agent value and URI specifi- cion for the agent
-
DefaultJitter: Jitter in agent reachback interval
-
Port: Listening port of the C2 server
-
StagingKey: Staging key for initial agent negotia- tion
-
ServerVersion: Server header for the C2 server.
HTTP listener provides -symmetric- encrypted communication even without SSL/TLS connection.
NIDS on Empire’s HTTP Listener
So let’s assume an agent is deployed on the network. After the initial negotiation, agent will connect to C2 in every n seconds which is de-fined in ”DefaultDelay” option of the listener. Here is a generic request and response of this heartbeat connection:
GET /read.php HTTP/1.1
Cookie: session=VAGyTO1KBPO0BxJ45BZrcm3BinQ
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36
Host: 192.168.1.26
Connection: close
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 208
Cache-Control: no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: 0
Server: Microsoft-IIS/7.5
Date: Thu, 08 Feb 2018 17:57:40 GMT
<html><body><h1>It works!</h1><p>This is
the default web page for this server.</
p><p>The web server software is running
but no content has been added.</p></
body></html>
We can list following traits which can be insight of an anomaly-based NIDS:
-
Request URI: As shown in the request above, agent makes it’s connection to the C2 server with a GET request to a specific URI (”read.php” in the example) If only html or aspx pages are in use on the local network, this ”php” extension may flagged by the anomaly detection system.
-
User-agent value: User-agent value defines the operating system and browser choice of the agent. For example, if all users on the network uses Microsoft Windows with Chrome, setting user-agent value to macOS with Safari browser, may flagged by the anomaly detection system.
-
Server header: Server header value defines the web server type of the C2. For example, if all the servers on the network are using Linux, setting server header as ”Microsoft-IIS” may flagged by the anomaly detection system.
-
Default HTML Content: This is related with server header. If only Linux systems are used on the network, IIS default page may flagged by the anomaly detection system.
-
Port: If only common ports like 80, 443, 8080 are used on the network, selecting communication port as 5839 may flagged by the anomaly detection system.
-
Connection Interval (DefaultDelay): By default, agent will send heartbeat request to the C2 server in every 5 seconds. If regular users are not connecting to a local server in every 5 seconds, this will be likely to flagged by anomaly detection system.
The last one is POST request body. Let’s check a generic POST request body of the agent-C2 communication:
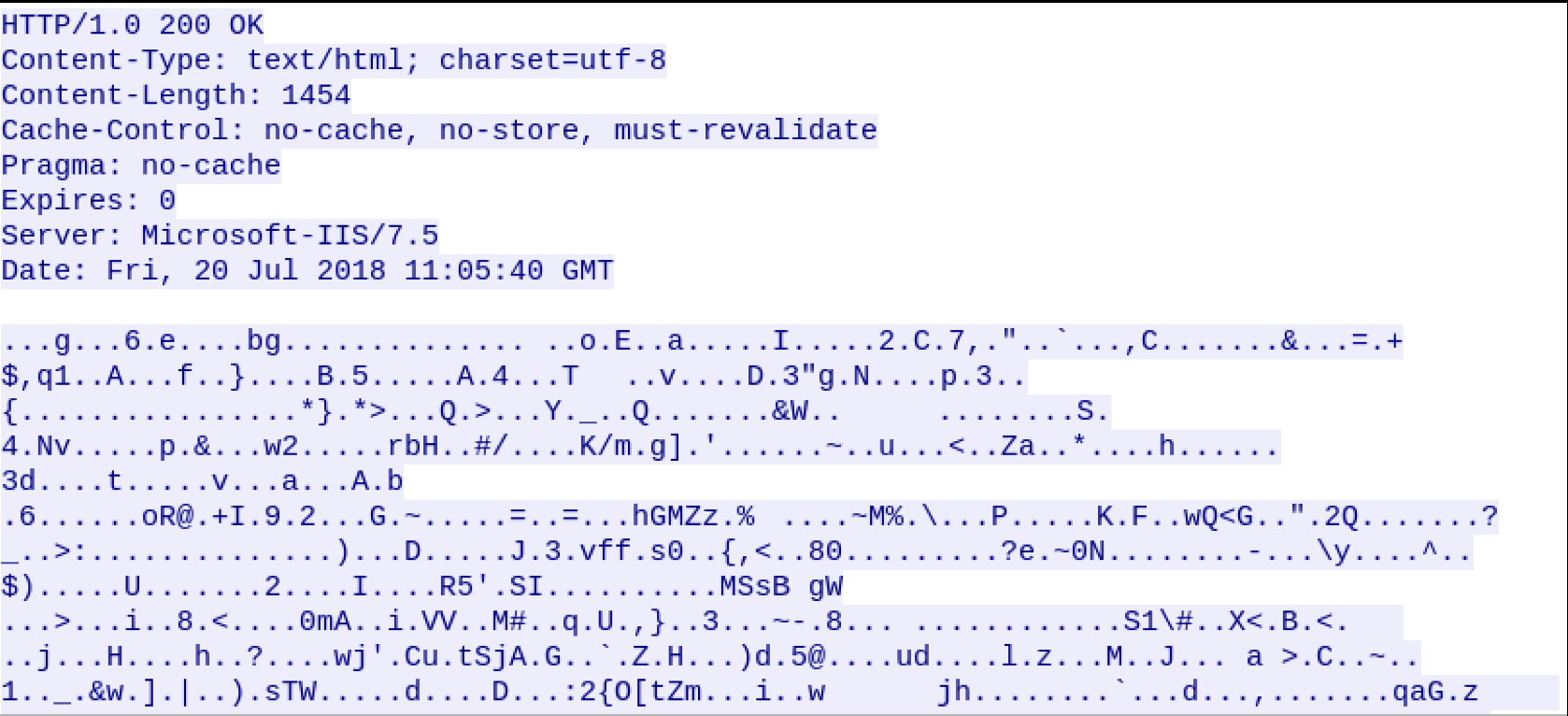
As seen in the example request, POST request body is encrypted and contains gibberish characters. If all users are browsing regular websites, this will be likely to flagged by anomaly detection system.
So we listed the traits which should be considered by an anomaly based system. We can gather the traits explained above in two different groups: Traits that can be changed in Listener’s option menu, traits that can be changed by changing Empire’s source code. Our tool, ”firstorder” won’t cover the second group. However, I will share my ideas anyway.
First group consists following traits: Request URI, User-agent value, Server header, Port, Connection interval
Second group consists following traits: Default HTML Content, POST Request Body
Proposed Solution
With which method, we can normalize the mentioned traits? The proposed solution is polymorphic blending attack. PBA is a useful technique to evade anomaly-based systems. From a high level of perspective, The idea is creating attack packets, which are matches to the normal traffic profile. To use this technique, attacker should know what is considered as normal. To do that, our model requires a traffic capture data of the network, after the normal traffic training is done. By checking the traffic capture data, our model will know what kind of traffic is used frequently. As a result, our main attack steps will be:
-
Get traffic capture data of a normal traffic and define normal behaviour of users.
-
Change Empire’s listener traits according to first step.
-
Start the C2-agent communication.
To normalize the first group of traits, we will extract most common URI, user-agent, server header and port values from the traffic capture data. With these data, we will set appropriate listener options. However, finding normal connection interval value is not an easy task. One way to do that is figuring the connection interval and frequency of users to the specific web sites. However, this solution will not be practical since there can be delays, interruption during traffic capture and this will affect the recorded connection interval of users.
The second solution relies on false-positive rates of anomaly detection systems. The false-positive rate of an anomaly detection system has a positive correlation with the size of the network. Which means that in a large network, even if we keep connection interval value small and get flagged by anomaly detection system, this will be most likely to be seen as false-positive by analysts. However, if we are located in a small network, we need to set connection interval higher than a pre-defined threshold. The disadvantage of this method is C2-agent communication will be delayed. It is a trade-off to keep our communication out of sight from the anomaly detection system.
For the second group of traits which are explained on previous section, default HTML content can be chosen by identifying most visited websites in traffic capture data. However, normalizing POST request body of the communication is not achievable by using traffic capture data. As it explained in previous sections, POST requests are encrypted and contains gibberish characters.
If we encrypt the POST request body, it gives us power over signature-based solutions, because it won’t match with any malicious signature. However, anomaly based systems will flag this since it’s not like a normal HTTP data. On the other hand if we don’t use encryption in there, our problem is bigger. Now, signature-based IDS will catch us since it may contains some malicious indicators such as “whoami”, “cat /etc/passwd” etc. Also anomaly based IDS will catch this, same reason with the previous one, it’s not like a normal http data.
Instead of directly encrypting the data, we can use Markov Obfuscation tool which is created by Cylance Spear Team. (https://github.com/CylanceSPEAR/MarkovObfuscate) . This is a great and very underrated tool. So lets check the overall process in a basic chart:
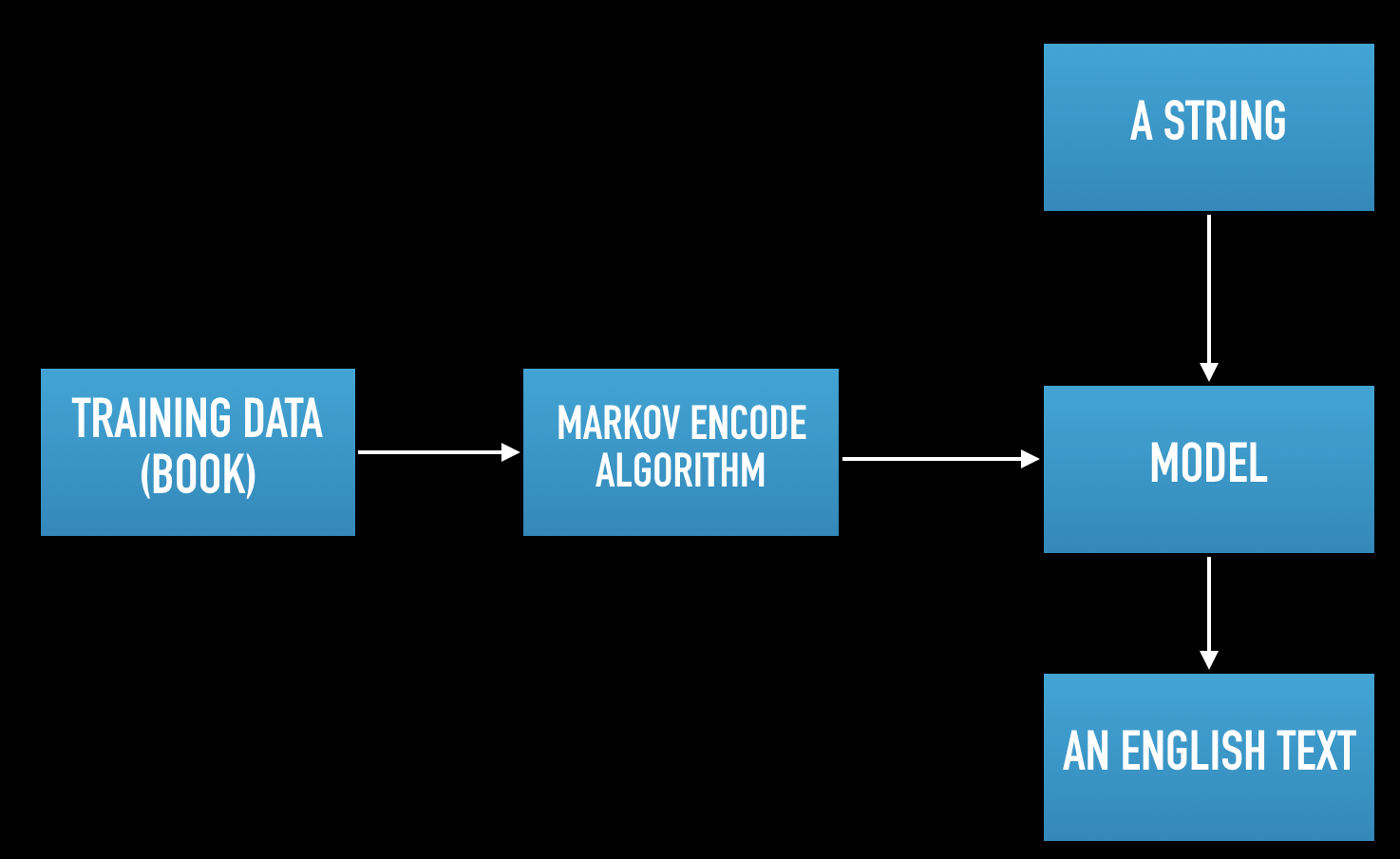
First, we need a training data which consists of lots of texts. Cylance team used a book for their demonstration. After then Markov Encode algorithm is trained by this text to build a model. When the model is built, it’s ready to encode any string, to a fairly meaningful English text.
For example this is the data of an “/etc/passwd” file. Normally, every IDS solution will flag this.
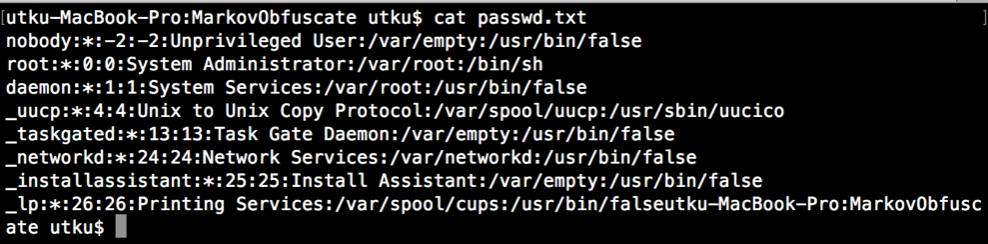
However, when we use an english book to generate a model, and encode that string with markov obfuscation tool, we got this result:
However, when it decoded by using same model, we will have the initial content of that “/etc/passwd” file.
So the operating steps will be like this:
-
First, we need to encode encrypted content with Base64 to get rid of gibberish characters.
-
As we talked we also need lots of texts which will be used as training data. One way to do it is including the training data inside the agent. However, it won’t be practical since it will increase the agent size like ten megabytes. Instead of that, we can download the dataset from an external source. It doesn’t have to be our own website. We can program it for crawling and parsing texts from news websites, blogs etc.
-
Train the Markov Obfuscation algorithm with downloaded training data.
-
Encode the data with generated model.
-
Send the encoded data to the C2 server, alongside with the training data.
-
C2 server will also build the same model with the training data, and will be able to decode the main data.
Since the anomaly-based system will only see some English texts, it will think that it’s kind of blog post or a forum comment. Probably won’t raise any alerts.
But there are some drawbacks of this method. The first one is the training phase will consume time and resource of the deployed computer. Time may not be a very big problem but if there is a centralized resource monitor solution located on the network, blue team may identify these resource usage spikes. The other drawback is you need to implement Markov Obfuscation code inside the agent. Because, it should do these by own it’s own, we can’t send it some commands and expect an output at that point. This issue will increase agent’s file size.
firstorder Tool
So we created a tool called firstorder, which is written in Python. With given PCAP file, firstorder can extract key features of the network such as most used ports, most used user-agent values, server headers, how many different machines out there etc. According to these identified data, it automatically configures Empire’s listener.
You can check the usage on it’s Github page: https://github.com/tearsecurity/firstorder
Conclusion
So as a result, defense mechanisms are evolving to something smarter, something better. Maybe in future, signature based apporoaches will be totally abondoned. And there is a high probability that machine learning based defense mechanisms will be cheaper and wider than today. So, attackers should also evolve in this way. We need to find smarter ways to mislead artificial intelligence.