
Generating Personalized Wordlists with NLP For Password Guessing Attacks
TL;DR
I coded a tool named Rhodiola which can analyze data about a target (for example target’s tweets) and detects most used themes in there and builds a personalized wordlist for password guessing. It’s an experimental project for creating a new approach for password guessing attacks.
Introduction
Passwords are our main security mechanism for digital accounts since the beginning of the internet. Because of that, passwords are one of the main targets of attackers. There are couple of major ways that an attacker can use to find a target’s password. The attacker can prepare a phishing website to trick a target into entering their passwords to a rogue website. Or, an attacker can conduct a password guessing attack through brute forcing. Password guessing attacks can be described in two main categories: online attacks and offline attacks.
Online password guessing attack is where the attacker sends username/password combinations to a service like HTTP, SSH etc. and tries to identify the correct combination by checking the response from the services. An offline password guessing attack is usually conducted against hashed forms of passwords.The attacker has to calculate a password’s hash with a suitable cryptographic hashing function and should compare it with target hash. For both online and offline attacks, the attacker usually needs to have a password wordlist. Most of the web applications have password complexity rules where users have to use at least one number, upper/lower case letters and a special character. Also there are lot’s of precautions such as IP blocking, account freezing etc. Therefore, reducing the number of trials is very important for attackers.
Mask Attacks
Mask attack is one of the main methods for reducing the brute force pool to an acceptable size. Mask attack refers to specifying a fixed password structure and generating candidate passwords according to that. For example, to crack ”Julia1984” as a password with pure brute force approach, we need to calculate 13.537.086.546.263.552 different combinations. But if we set a mask with its structure, we can reduce the combination pool to 237.627.520.000. But of course, it’s still too much for the online attacks. We usually can’t send two hundred billions request to an application over internet.
Sherlock’s Way
However, pure brute force and mask attacks are not the only way for password guessing. There is also a science fiction method based on smart guessing. For example on Sherlock’s Hound of Baskerville episode, Sherlock Holmes was checking personal stuff of the target and were guessing the correct password in one shot. But how can we do it in real life?

Let’s assume that target is posted that tweet and we are a Sherlock Holmes candidate. We can make following deductions: target’s daughter name is Julia and target loves her so much since he or she tweets about her. And target’s favorite author is George Orwell, who’s most popular book is 1984. So combine them together, the answer is “Julia1984” Is this that simple?
According to experiments conducted by Carnegie Mellon and Carleton universities, most people are choosing words for their passwords based on personal topics such as hobbies, work, religion, sports, video games, etc.[1][2] This means that most of the user passwords are contains meaningful words and they are related with the password’s owner. So in theory, we can become a sherlock holmes on password cracking. Let’s validate this.
Analyzing Myspace and Ashley Madison Wordlists
When we analyze leaked Myspace and Ashley Madison password lists with PACK (Password Analysis and Cracking Kit) and generate the most used masks, we can see that almost 95% percent of the passwords are formed by sequential alphabetic characters. So there is a high probability that these are meaningful words. Some of the most popular masks are:
?l?l?l?l?l?l: 7%
?l?l?l?l?l?l?l?l: 7%
?l?l?l?l?l?l?l: 6%
?l?l?l?l?l?l?d?d: 4%
?l?l?l?l?l?l?l?l?l: 4%
Since both Ashley Madison and Myspace wordlists are mostly consists of sequential alpha characters, there is a high probability that they are meaningful words. If they are somehow meaningful, we can fill the mask with meaningful words instead of brute forcing the characters. The first step is understanding if a letter sequence is a meaningful word in the English language. We can state that a letter sequence is an English word if it’s listed in an English lexicon. I used Wordnet as the lexicon. The analyze is showed that almost fourthy percent of those wordlists are included in Wordnet lexicon, hence they are meaningful English words.
After it’s confirmed that the letter sequence is included in Wordnet, hence it’s an English word, we need to do part-of-speech tagging (POS tagging). There are eight parts of speech in the English language: noun, pronoun, verb, adjective, adverb, preposition, conjunction, and interjection. POS tagging is the process of marking up a word in a text as corresponding to a particular part of speech. NLTK Python library is used for POS tagging.
To understand which part of speech is usually located in human-designed passwords, we’ve analyzed Myspace and Ashley Madison wordlists again.. The code that was used to analyze named ”word classifier.py” is located in here The result showed that most of the words are singular nouns (32%)
If we use all words in the Oxford English Directory, the combination pool will be 171,476. If we use ”?l?l?l?l?l?l” mask to brute force all six-character alphabetic strings, the combination pool will be 308.915.776. So, trying all English words in dictionary would be 1801 times faster than using a mask. But 171,476 is a still big number for online attacks.
Sherlock’s Way (Again)
So let’s recap what kind of facts that we have so far. First, our analyze is showed that people are using meaningful words for their passwords. And the second, from the research conducted by various of universities, we know that passwords are mostly based on personal topics. So Sherlock Holmes method is legit in theory. But can it be done in practise? What Sherlock Holmes did was analyzing personal topics about the target. Then, he combined them in his mind and came up with a candidate password.
But can we do it in real life? To achieve this, we need information about target and an algorithm which extracts good password candidates from that information. We need a data source about the target just like Sherlock Holmes had. We need a source where we can find hobbies and other interest areas of the target. We all know that kind of source. It’s Twitter of course. In Twitter, people are tend to write posts about their hobbies and other interest areas. Since there is a character limitation for the tweets, users should write things more focused. And this make things easier for us. We don’t need to deal with large, gibberish texts. So let’s use the Twitter as a data source and try to build our personalized wordlist generator algorithm.
Building the Algorithm
Downloading and Cleaning Tweet Data
First of all, we need to gather tweets from target via Twitter’s API. Since our goal is to identify a user’s personal topics and generate related words about it, we need to remove unnecessary data (stop words) from downloaded tweets. Both NLTK’s stopwords extension and a custom list are used. Lists contains high-frequency words like ”the,a,an,to,that,i,you,we,they”. These words are removed before processing the data. We also removed verbs since passwords are mostly contains nouns.

Identifying Most Used Nouns and Proper Nouns
As shown in the previous section, almost 32% of the user passwords are consists singular nouns. Therefore, our first goal is to identify the most used nouns and proper nouns. The topics that the user is interested most can be identified with them. The most used nouns and proper nouns are identified with NLTK’s POS tagging function. For the example tweet above, nouns are: author and daughter. Proper nouns are: George Orwell and Julia.
Pairing Similar Words
In some cases, nouns can be used together. To create meaningful word pairs, we need to analyze their semantic similarities. For this purpose, NLTK’s path similarity[16] is used with the first noun meaning (n.01) on Wordnet for all identified nouns. The path similarity returns a score denoting how similar two word senses are, based on the shortest path that connects the senses in the is-a (hypernym/hyponym) taxonomy. The score is in the range 0 to 1. Our algorithm pairs any two nouns if their similarity score is higher than 0.12.
Finding Related Helper Words
Researchers have found that some of the most used semantic themes in passwords are locations and years. Therefore, related locations and years to a user’s interest areas should’ve been found. Wikipedia is used for both works. Our algorithm visits each proper noun’s Wikipedia page and parses years with regex and identifies city names with its hardcoded city list. In the example tweet above, when we send “George Orwell” to Wikipedia, our algorithm will parse words such as London, 1984 etc.
Combining Everything
The last step is combining all of our data. From the example Tweet we got George Orwell word, we sent it to Wikipedia and it returned us 1984. Beyond that we also had Julia as a proper noun. So when we combine all of our data, we will have the correct password “Julia1984” in somewhere in our wordlist. So instead of millions of combinations, we could crack this password just like Sherlock Holmes.
Rhodiola Tool
Rhodiola is written in Python 2.7 and mostly based on NLTK and textblob libraries. With a given Twitter handle (If you don’t have that one, you can bring your own data. Check the Github page for details), it can automatically can compile a personalized wordlist with the following elements: Most used nouns&proper nouns, paired nouns&proper nouns, cities and years related to detected proper nouns. For example:
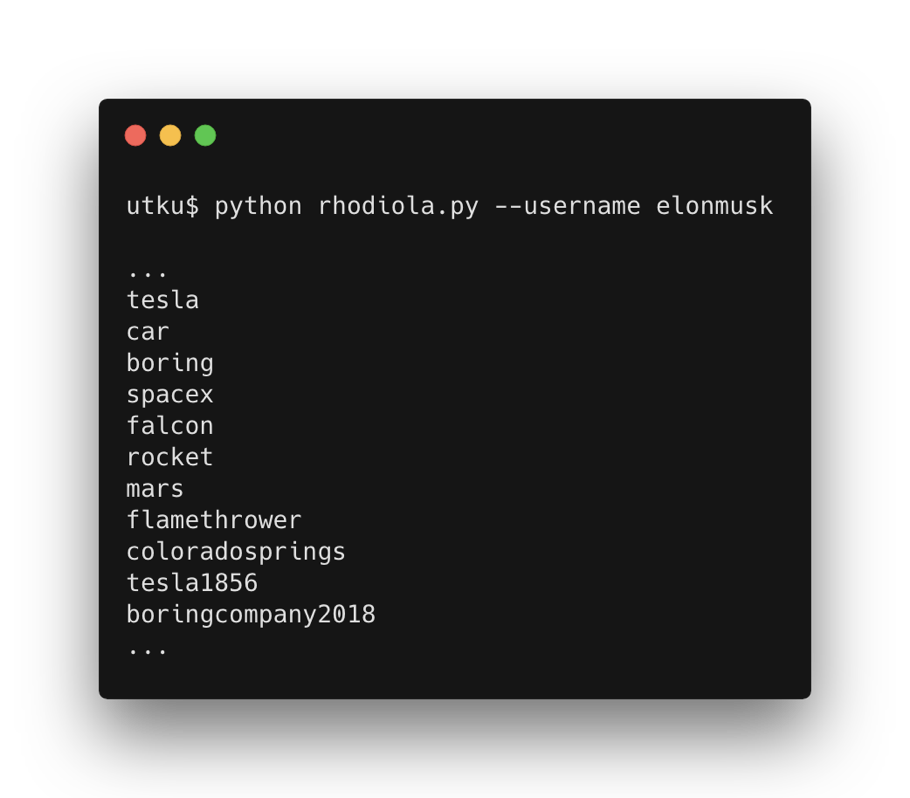
For detailed usage check it’s Github page: https://github.com/tearsecurity/rhodiola
Conclusion
Since people tend to use words from their interest areas for their passwords and expose those interest areas on Twitter, it’s possible for an attacker to create a wordlist by analyzing a target’s tweets. Beyond Twitter, any actor that has much more data about a person will have an ability to create more accurate wordlists. Therefore, users should avoid using words from the topics that are exposed in social media. It’s better to use random passwords that are stored in a password manager software.